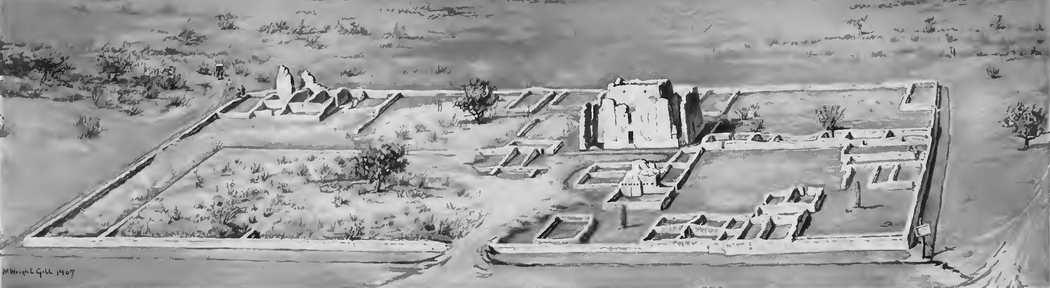
The 87th Annual Society for American Archaeology (SAA) meeting will be starting this week and Digital Antiquity staff will be in attendance, participating in a variety of forums and poster sessions other events in rainy Chicago!
One particular poster session will showcase the DAHA project and usage statistics for the collection. If you are unable to make it to the conference, you can find the poster and its associated data on tDAR!
Digital Antiquity staff will also be on hand at Exhibit Hall booth #103 throughout the week, so be sure to stop by with any tDAR or digital curation related questions, learn more about the SAA/Center for Digital Antiquity Good Digital Curation Agreement, enroll in our raffles to win some great prizes, or just stop by to say hi!
Follow us on Twitter @DigArcRec and Instagram at @digitalantiquity for up-to-the-minute tDAR news throughout the conference!
Thursday, March 31, 2022
Digital Antiquity Booth
Room: Exhibit Hall
Booth #: 103
Time: 9:00 AM – 5:00 PM
Forum: [36] Exploring Data Stewardship with tDAR, Open Context and DINAA
Room: Continental C
Time: 1:00 PM – 3:00 PM
Friday, April 1, 2022
Digital Antiquity Booth
Room: Exhibit Hall
Booth #: 103
Time: 9:00 AM – 5:00 PM
Poster: [113] Digital Archaeology Across North America
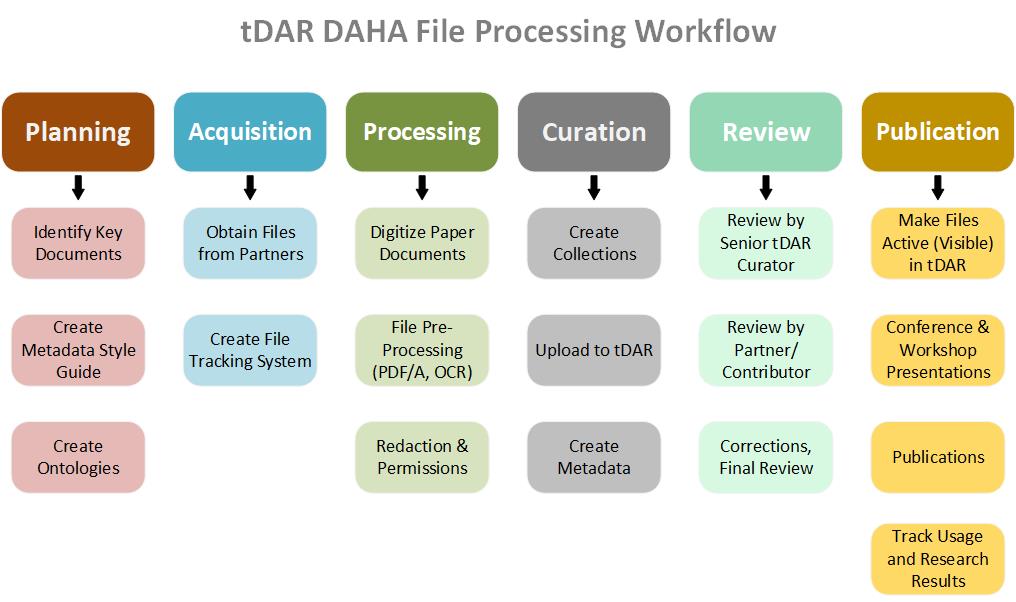
Digital Antiquity staff developed a comprehensive and reliable digital curation workflow designed to process DAHA documents in a consistent, timely and cost‐effective manner. This ensured quality control and helped to maximize the research value of the DAHA Archive.
Planning, Document Selection and Acquisition
DAHA project leaders identified and contacted more than 15 organizations that are, or have been, major producers of Huhugam research and analysis. Selection focused particularly on organizations that had important collections of unpublished grey literature reports. A majority of the projects undertaken in the U.S. over the last 50 years have been carried out by commercial firms or government agencies and reported only as unpublished grey literature. These documents are extremely valuable because they are professionally written, rich in technical detail, and carefully edited but distributed—usually in paper—in very small numbers. Our success in addressing some of archaeology’s most important questions hinges on our ability to gain access to this wealth of information. The inclusion of more than 2,000 grey literature documents in DAHA provides easy access as well as preservation into the future.
The other selection criterion was a focus on project reports and analyses, rather than field notes or artifact lists. Partner organizations were asked to identify relevant Huhugam documents and data sets in their possession, ones that they were willing to contribute to tDAR for public access. Since our partners provided paper reports as well as digital files, a file tracking system was established to monitor the different paper vs digital curation steps (see below).
As a final planning step, a DAHA Metadata Style Guide was created to promote consistency among the various digital curators working on the project. A style guide is a document that provides specific instructions and examples for each tDAR descriptive metadata element (https://www.tdar.org/using-tdar/upload-toolkit/#developingAMetadataStyleGuideData). The DAHA style guide ensured that each document was richly described using a shared vocabulary so that similar or related documents are linked to each other in tDAR.
Processing and Digital Curation
Once selected and acquired, paper documents entered a standard processing workflow, a series of efficient, well-documented steps that could be carried out by student workers as well as Digital Antiquity staff members. If the report was born digital, the same processing steps were followed starting at Step 4. These steps included:
Unbind (if necessary);
Scan using a sheet-feeder and appropriate dpi settings;
Scan rare or valuable reports using a book scanner;
Optical Character Recognition (OCR) using ABBYY FineReader;
Convert to PDF/A;
Review for confidential and/or sensitive material and redact if necessary;
Create metadata based on the tDAR basic metadata schema and the DAHA Style Guide;
Upload the original file and the redacted PDF/A to tDAR.
Metadata entry is a key part of the curation workflow. tDAR has an interactive interface that standardizes entry of bibliographic and descriptive metadata, provides tools to identify geographic and temporal contexts, and has menus to add contact information for associated individuals and organizations.
Finally, DAHA was organized into a number of overlapping collections, each of which may have sub‐collections. A collection identifies a logical grouping of related tDAR files and aids discovery and resource administration. For example, a collection has been created for each partner organization; other collections have been built topically.
Review
All documents were reviewed by digital curators to correct scanning or metadata errors, but also to determine whether the document contained sensitive or confidential information. Confidential information is information that should have restricted dissemination due to the reasonable risk of vandalism or looting of archaeological resource(s). The Archaeological Resource Protection Act (ARPA) and the National Historic Preservation Act (NHPA) restrict the release of information about specific locations and/or characteristics of sites covered by these laws if the public release of such information might result in damage to or loss of the site. Sensitive information is information that may be culturally offensive to some individuals or groups. The Center for Digital Antiquity has a “Treatment of Confidential and Sensitive Content in the Digital Archive of Huhugam Archaeology” document that outlines the DAHA review process, available on the DAHA website.
During review, sensitive or confidential content was flagged and redacted. An unredacted version of each document was preserved and a redacted copy created. The unredacted version was uploaded to tDAR but marked as confidential and access restricted. The redacted copy was uploaded and is the version that is visible in tDAR and available for download.
As a final review, the partner organization that contributed the file was invited to review the document, any redaction (if present) and all metadata. Files remained in “Draft” form until completion of the full review process. Draft documents and metadata records are not publicly visible or accessible. Only after the review process was completed were documents made visible (Active) in tDAR.
Publication, Dissemination and Outcome Tracking
Once the review process was completed, DAHA staff changed each document’s status to “Active,” making it visible and available for download. The metadata related to public files in tDAR is indexed by search engines like Google, increasing the findability of the DAHA corpus.
A variety of approaches were taken to help publicize and disseminate the DAHA library. One important communication venue was the DAHA project website. The website was created during the first year of the project as a means of publicizing results and facilitating communication with various user communities. The Center for Digital Antiquity will continue to host the website as a useful companion to the Archive in tDAR. In addition to answering common user questions, the FAQ page provides a mechanism for users to send feedback about the site, ask additional questions, or contribute new material to DAHA. The blog posts and news items provide detailed descriptions of various aspects of the project
Digital Antiquity collects anonymized download and usage data that allows us to track how people discover and use the records in tDAR. Over the next several years Digital Antiquity staff will compare usage data for DAHA files (e.g., downloads, links, and views) with average usage metrics for other collections. This will help track the success of the DAHA library and also help evaluate the success of conference presentations, public presentations and other DAHA related publication events.
DAHA project staff will prepare articles targeted to communities of interest, such as Archaeology Southwest and the Arizona Archaeological Council Journal of Arizona Archaeology. Project staff will also submit articles to The SAA Archaeological Record, Advances in Archaeological Practice, and Digital Humanities Quarterly. Finally, papers will be presented at annual meetings of the Society for American Archaeology. In calendar year 2022, DAHA staff will host an Arizona Archaeological Council workshop exploring the research uses of the DAHA corpus.
The Center for Digital Antiquity (DA) utilizes a detailed policy for the treatment of sensitive and/or confidential documents for projects that are uploaded to tDAR by DA staff. For the DAHA project, Digital Antiquity staff reviewed that policy and consulted with representatives of the Cultural Resources Working Group of the Four Southern Tribes. This document outlines the policy as it was applied to documents added to the DAHA archive.
Treatment of Confidential and Sensitive Content in DAHA
Confidential Information is information about the location or nature of any archaeological resource or historic property the disclosure of which would create a risk of harm to the resource. Federal officials responsible for archaeological resources or historic properties covered by the Archaeological Resource Protection Act (ARPA, 16 U.S.C. 470aa-mm) and the National Historic Preservation Act (NHPA, 54 USC 300101 et seq.: Historic Preservation) are required to restrict access to information about the nature or location of these resources unless release of the information would further the purposes of the statutes and not create a risk of harm to the resources. In practice, the information most commonly regarded as confidential is very specific location information about archaeological resources. Sensitive Information is information that may be culturally offensive to some individuals or groups.
All confidential information in documents in DAHA has been redacted and spatial locations have been obfuscated on website maps. A full, unredacted version has been uploaded to tDAR but marked as confidential. Access to this version is strictly controlled and requires permission from the contributor. The redacted copy of the document in tDAR is publicly available for viewing and download.
All sensitive information in DAHA documents has also been redacted. This includes images, drawings, photographs or other representations of human remains or burials. As described above, an unredacted version has been stored in tDAR but is confidential and requires permission from the contributor in order to receive access. The redacted version is publicly available for viewing and download.
As a standard step in the Digital Curation workflow, each DAHA document was reviewed by a trained digital curator who searched for both confidential and sensitive information throughout the report. Content that was found was flagged for redaction. Next, a senior digital curator reviewed that document and verified that all sensitive and/or confidential information had been flagged and redacted. Finally, each contributor or DAHA partner was asked to review the documents belonging to their collection, looking in particular at any sensitive and/or confidential content that might be present.
In October, 2017 the DAHA team designed a survey to assess the relevant information-related needs of the Digital Archive of Huhugam Archaeology’s key user communities: archaeologists and others working in cultural heritage management who are concerned with Huhugam archaeology. We wanted to distribute the survey to as many Huhugam archaeologists as possible so we sought the help of the 177 members of the Arizona Archaeological Council (AAC). This is the professional organization of archaeologists working in Arizona. Although most AAC members are not Huhugam archaeology specialists, we thought this group contained much of the audience we were targeting. We also contacted an additional 28 Huhugam archaeologists not affiliated with AAC. Most individuals received an initial email request to participate (containing the link to the survey) and at least one email reminder.
Between 18 October and 30 November 2017, we received 49 anonymous responses. We were encouraged by the 24% response rate, especially given that the distribution included a substantial number of individuals for whom the survey was not relevant. The survey was designed to elicit a reasonable number of responses from the community of Huhugam archaeologists and it was successful in that regard; it was not designed to obtain a statistically representative sample.
We published the full DAHA User Survey Report in the “Reports in Digital Archaeology Publication Series.” Reports in Digital Archaeology is an online publication series devoted to issues regarding research and practice in digital archiving of archaeological materials and archaeologically related data. Below are some of the survey highlights.
Analysis of the Results
Because the goal of the survey was to provide feedback from Huhugam archaeologists for use in developing the DAHA archive, the questions were focused primarily on two areas: what research questions are of most interest to the user communities, and what IT tools and technological support would enhance and expand the user experience with the DAHA digital library in tDAR.
The results confirmed our beliefs that there is a perceived need for DAHA and that the archive will be heavily used by Huhugam archaeologists. The survey’s responses on how archaeologists use reports and what features they want to see in DAHA indicate that we should focus development on features that facilitate efficient discovery of the desired documents and that allow users to find or extract specific types of information they are looking for within reports. The results are helpful in both prioritizing the kinds of resources to add to DAHA, and for the development of natural language processing (NLP) tools.
Table 1. What do you see as the three most important questions in Huhugam Archaeology?
Count
Subject
21
Understanding the End of Classic/Huhugam Collapse
16
Huhugam Connections to Descendent Communities
14
Huhugam Organization
11
Preclassic/Classic Transition
10
Internal Hohokam Interaction
9
Adaptation to Environment
7
Identity/Ethnicity/Ideology
7
Modeling/Refinement of Population
6
Methods Issues
5
Water Management/Irrigation/River Flow
5
Relevance to today
5
Subsistence & Production
4
Chronology Refinement
4
Early Agricultural to Pioneer Period
4
External Interaction – Including with Mesoamerica & Pueblo areas
3
Nature of Classic Period
3
Huhugam Origins
3
Resilience of Huhugam
Several survey questions provided valuable information concerning the research topics of most interest to the user communities (Table 1). Those results will likely be of interest to many Hohokam archaeologists, and will help structure the organization of the final DAHA archive, as well as provide guidelines for decisions about the most important documents to include in the archive.
Table 2. What features would help you in using grey literature reports to advance knowledge of Huhugam society?
Count
Feature
13
Keyword Search/Index to reports [already implemented]
12
Full Text Search [already implemented]
4
Good Abstracts/Summaries of Scope & Results
3
Master (Annotated) Bibliography of Huhugam Reports
3
Spatial Search [already implemented]
2
Extract Tables as Spreadsheets
2
Organization Search Output to Facilitate Selection
2
Topic Search
1
List of Analysis Types Reported
1
Indication if Full Text is Available in Search Result
1
Indication if Report is Peer Reviewed or Agency Approved
1
Abstract preview before download [already implemented]
1
Quick Response Time
1
Partial Download
1
Connect Tabulated Data with Associated Text
1
Integrate with AZSite
1
Voice Search
A later question (Table 2) was most useful in directing the development of natural language processing tools and adding or enhancing tDAR search and access features. The two most common requests shown in Table 2, keyword and full-text search, are core features built into tDAR from its beginning. The report abstracts are generally extracted and made available on the metadata pages as the document summary. Like full text and keyword search, spatial search is a core feature of tDAR available from the beginning. Being able to extract document tables as spreadsheets is a challenging request that we are considering.
Question by question and full text survey results are available in tDAR:
If you Google “archaeology” and “text mining” you get a pretty small number of results. While both the Archaeology Data Service (ADS) in the UK and Open Context, the American open data and publication service, have worked on projects that apply text mining techniques to archaeological reports, it is probably safe to say that most archaeologists are unfamiliar with how text mining or data science can contribute to archaeological research. This isn’t surprising since most of us specialize in the analysis of some material culture product, not the analysis of written reports. But as McManamon et al. (2017) have pointed out, the volume of new archaeological articles, books, compliance reports and other documents is so large, and grows so quickly, that no one person can possibly read it all. Text mining offers automated approaches that help with this “data deluge.”
This past April, the Digital Archive of Huhugam Archaeology (DAHA) team hosted an NEH-funded research workshop focused on Archaeology and Text Mining. Led by DAHA investigators Michael Simeone, Keith Kintigh and Adam Brin, we invited 9 panel experts including archaeologists, Native American scholars, and Digital Humanities researchers, to meet with the DAHA team for a day of discussion. We asked the panelists first to simply talk about how they use digital texts in their work, regardless of their discipline.
Working in small groups, the participants discussed the epistemology of research for their respective fields and quickly turned the conversation to the how text mining digital documents could benefit each field. Ideas such as pulling artifact counts and site descriptions from standardized CRM reports to demographic studies were mentioned. Professor David Abbott, a Huhugam Researcher in ASU’s School of Human Evolution and Social Change, brought up the potential for text mining to advance synthetic research.
Next, we wanted to hear their ideas about how we might make the DAHA digital text corpus more useful to a broad and diverse audience with text mining. Joshua MacFadyen, Assistant Professor of Environmental Humanities in the School of Historical, Philosophical, and Religious Studies, and the School of Sustainability at ASU, brought up this important question on user experience and how we are able to record and trace this impact of these tools on a diverse user group. In addition, David Martinez, member of the Gila River Indian Community and Associate Professor of American Indian Studies at ASU, hopes that this technology can potentially bridge the gap between community users and researchers and allow the users to interpret data in ways that interest these communities. Overall, text processing was thought to be most useful in aiding filtering and analysis of data, rather than providing direct insights.
Finally, we asked all the participants to reflect on what we accomplished and identify useful directions the DAHA team can take in using Text Mining tools and technology. Some of the possible features to come out from DAHA include: automated tools for the extraction of specific text sections, such as tables, references, or headings, use of ontologies to make documents more efficient, topic related searches, and the ability to gather set of reports and have the data linked to its various sources.
Corpus Statistics (Word frequencies across corpus)
Concordance
N-Grams
Advanced queries across multiple texts
Named Entity Recognition
Topic Modeling
Sentiment Analysis
Network Analysis
Text visualization options
GeoParsing (geographic information extraction)
If you are interested in applying text mining tools to a document corpus of importance to you, there are several good, open source toolkits that support one or more approaches:
AntConc (http://www.laurenceanthony.net/software/antconc/ ) is an easy-to-use set of tools for analyzing any type of text corpus. AntConc provides tools to calculate word frequency, concordance, N-Grams, and corpus statistics.
ConText (http://context.lis.illinois.edu/ ) is a package of tools that allow you to do topic modeling, sentiment analysis, parts-of-speech analysis, and visualization of a text corpus.
MALLET (http://mallet.cs.umass.edu/index.php ) MAchine Learning for LanguagE Toolkit is a very popular topic modeling tool.
Ora-Lite (http://www.casos.cs.cmu.edu/projects/ora/software.php ) is a software package that helps you identify and visualize networks (e.g., people who communicated with each other or places that are linked) in text data.
Voyant (https://voyant-tools.org/docs/#!/guide/start ) is a free online service that supports a number of corpus analysis tools, including visualization.
_______________________
1 McManamon, Francis P., Keith W. Kintigh, Leigh Anne Ellison, and Adam Brin. 2017. “The Digital Archaeological Record (tDAR): An Archive – for 21st Century Digital Archaeology Curation” Advances in Archaeological Practice 5(3), pp. 238–249.
The lively and well-attended Arizona Statewide Historic Preservation Conferencewas held earlier this month at the Hotel Valley Ho in Scottsdale. The Center for Digital Antiquity organized two sessions for the conference.
Organized by Leigh Anne Ellison, who summarized the various aspects of DAHA, presentations also were made by David Martinez, Frank McManamon, and Adam Brin. Martinez described the dialogue with tribal communities as part of the project. McManamon summarized the building of content for DAHA in a collection in tDAR, the Digital Archaeological Record. Brin summarized research on natural language processing and “text mining” as part of the project that will enable more detailed research on the rich body of technical reports and other documents assembled in the digital archive. Learn more about this and our other session here.
For the DAHA Project we tested various NLP systems including NLTK, Stanford, GATE, and Apache OpenNLP. To evaluate them, we extracted a 10-page section of “FRANK MIDVALE’S INVESTIGATION OF THE SITE OF LA CIUDAD” by David R. Wilcox (tDAR # 4405), and ran the text through each of the tools at their base settings, and then through a tool that stripped out artifacts from the Object Character Recognition (OCR) process. We then grouped and ranked the results comparing them to a baseline run by a person. Each unique result was validated and counted as valid or invalid, using the human recognition as the baseline, though in a few cases, the human missed values, or miscounted values. The result was a mostly quantitative analysis of the different engines and an attempt to rate the quality of each system.
Institution
Person
Location
Engine
found
valid
invalid
found
valid
invalid
found
valid
invalid
human
35
32
3
62
62
0
27
22
4
stanford
43
23
18
69
46
17
45
21
25
apache
42
24
15.5
29
25
3
31
11
19
apache (2 hour training)
42
24
15.5
47
45
3
31
11
19
gate
0
0
0
66
37
18
1
1
2
NLTK
78
9
69
102
37
65
2
1
1
The results showed that out of the box, the Stanford tool was definitely more accurate, although it had a number of invalid matches too. The NLTK was the most aggressive and had the most matches, and invalid matches (except for locations). The Apache toolkit did pretty well with the ratio of valid matches to invalid ones. It seemed successful enough, that a few hours were spent on determining if it could be easily trained to improve the match quality. The results with “people” were quite good. Stanford found initialized names (E. K. Smith) while the Apache tool did not. We were able to train the Apache tool quite easily to recognize this format. We also were able to train the Apache tool to identify citation references e.g. (Smith 2017) which also would improve the matches.
Engine
Institution
Person
Location
human
100.00%
100.00%
100.00%
stanford
71.88%
74.19%
95.45%
apache
75.00%
40.32%
50.00%
apache (2 hour person training)
75.00%
72.58%
50.00%
gate
0.00%
59.68%
4.55%
NLTK
28.13%
59.68%
4.55%
Based on the ease of training the Apache tool, and the challenge of the Stanford tool’s license, which makes it more difficult for integrating it into tDAR infrastructure, we plan on moving forward with the Apache OpenNLP toolkit. One other note on GATE was the challenge of configuring it.The results showed that the out of the box, the Stanford tool was definitely more accurate, although it had a number of invalid matches too. The NLTK was the most aggressive and had the most matches, and invalid matches (except for locations). The Apache toolkit did pretty well with the ratio of valid matches to invalid ones. It seemed successful enough, that a few hours were spent on determining if it could be easily trained to improve the match quality. The results with “people” were quite good. Stanford found initialized names (E. K. Smith) while the Apache tool did not. We were able to train the Apache tool quite easily to recognize this format. We also were able to train the Apache tool to identify citation references e.g. (Smith 2017) which also would improve the matches.
By Keith Kintigh, Adam Brin, Michael Simeone and Mary Whelan
When people talk about the problems, and potential, of Big Data they are often referring to research or business output files that are gigantic. But an equally vexing Big Data problem involves wrangling thousands of small files, like PDFs. Addressing this problem is a key component of the NEH funded DAHA Project because we anticipate that the DAHA library will contain over 1,600 grey-literature archaeological reports, on the order of 400,000 pages of information-rich text. Our ultimate goal is not to sequester these documents in the archive, but to stimulate and enable new uses that advance scholarship. For efficient ways to search and analyze that many documents at once we turn to computer science and Digital Humanities, using Natural Language Processing (NLP) tools developed and applied in those disciplines.
Natural Language Processing tool kits that we compared for the DAHA project
Of course you can do a simple word search in the DAHA archive in tDAR now and get useful results. But word searches have limitations (spurious results, spelling variations missed, etc.) and ultimately what we would like to do is search the entire corpus using a complex query like “Find all the reports that describe 12th century excavated pit structures from New Mexico or Arizona that have a southern recess and are associated with above-ground pueblos with 10 or more rooms.” We aren’t there yet, but NLP approaches and tools are moving us closer to that goal.
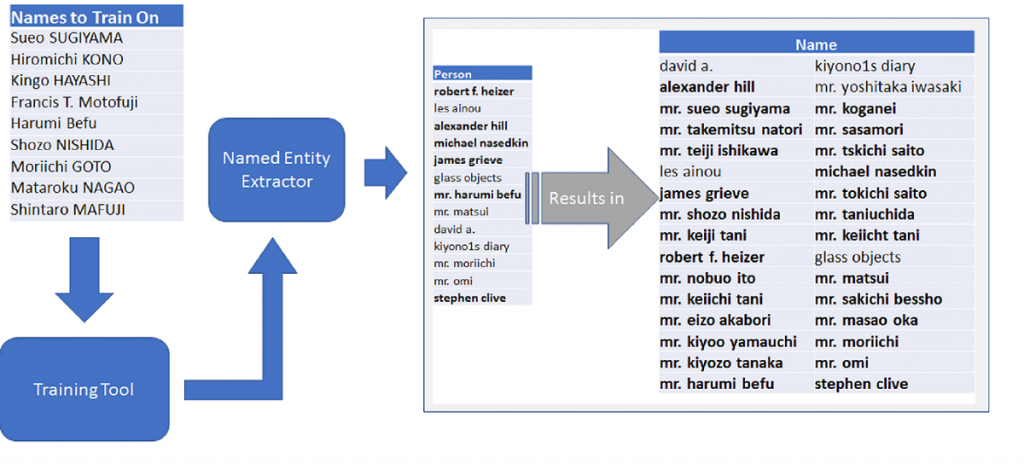
For the DAHA project, we are focusing on the NLP branch known as Named Entity Recognition (NER). Working with this framework in tDAR will allow us to automatically extract standard who, what, where, and when references from each DAHA document, thus improving metadata records which will greatly improve a user’s query and discovery experience.
Preliminary workflow for DAHA Named Entity Extraction tasks
So far we have started to figure out a workflow, identified a test set of DAHA documents and asked a human to tag words and phrases in one document. Our entity tags include Ceramic Type, Culture, Location, Person, Institution, Archaeological Site Name, Site Number and Date. Next we experimented with three NER tool kits (Stanford’s NLP Toolkit, Apache’s Open NLP, and the University of Sheffield’s GATE) to see which one(s) worked best on our corpus. We’ll describe our NLP comparison and results in detail in the “Natural Language Processing and the Digital Archive of Huhugam Archaeology – Part II” blog post.
The DAHA Project is underway. Funded by the National Endowment for the Humanities, the goal of the Digital Archive of Huhugam Archaeology (DAHA) is to create a comprehensive library of archaeological reports focused on the Huhugam (Hohokam). As we collect new documents from various people and organizations we would ideally like to automatically add as much metadata to the digital files as possible. One widget already in place in tDAR (the digital repository that holds the DAHA collection) is a map feature that lets contributors click on the map to identify the location the document refers to. One click on the map automatically generates geographic key words such as state or province name, country name, and other landmarks where the click intersects. For DAHA purposes, we want to add Huhugam geographic subareas to the tDAR map to generate additional key words (subarea names) for this project. This additional metadata enhances and improves searching.
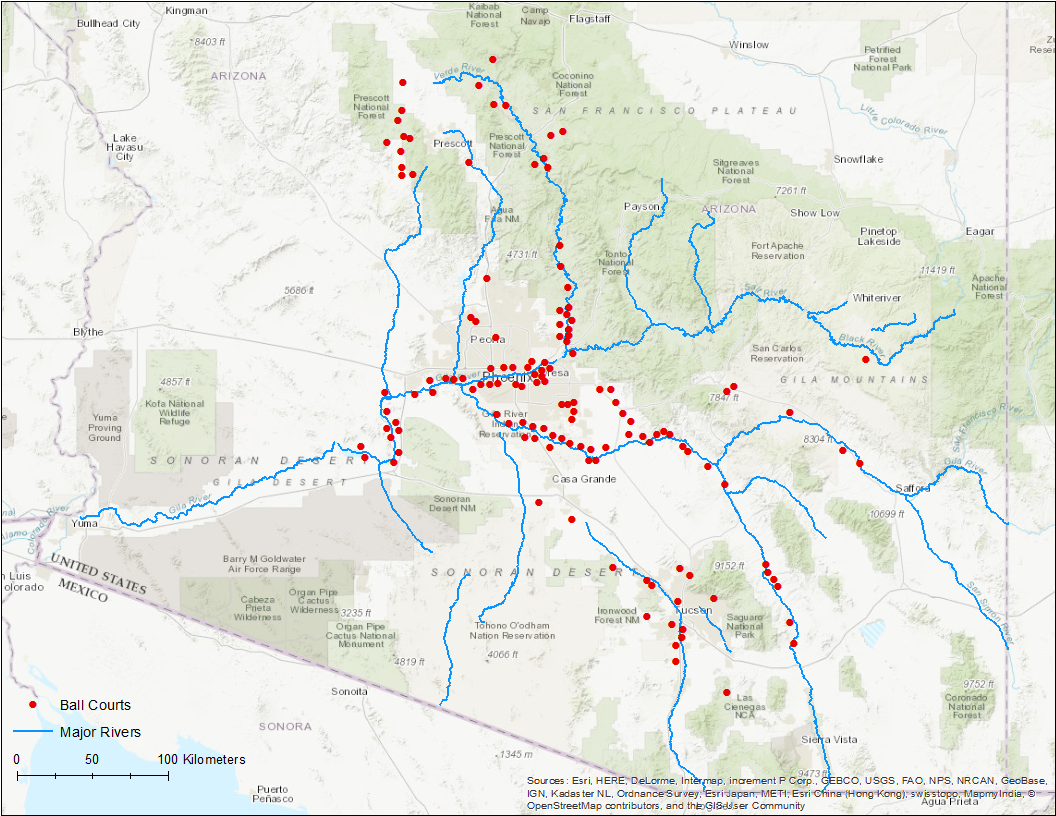
Huhugam sites are found throughout central and southern Arizona, most located in the river valleys that helped make agriculture sustainable in an otherwise challenging desert environment. Archaeologists conceptualize Huhugam “culture” as a set of geographically separate but interacting communities spread across a large territory and integrated with one another through the exchange of goods and services (Abbott et al. 2007). The regional extent of Huhugam culture is impressive, over 80,000 km2 (31,000 mi2) at its maximum.
Archaeological sites with ballcourts in the Huhugam region
Regional integration was both facilitated by, and is illustrated through, the construction and use of ballcourts – large, oval excavated features that were likely used for a ritual ballgame inspired by similar Mesoamerican practices to the south. Periodic marketplaces, timed to coincide with the ballgames, may have been instrumental for moving high volumes of goods throughout the Hohokam territory. Mapping the extent of sites containing ballcourts is one way to delimit the Huhugam regional system boundaries (map above).
Scholars working in the Huhugam region often refer to smaller subareas named for location (e.g., Phoenix Basin, Tucson Basin) or watershed (e.g., Lower Verde River, Santa Cruz River) (see Craig 2001, Wilcox and Sternberg 1983, Abbott et al. 2007). For the DAHA project we need to delineate these subareas so that we can create a map that will support the automatic metadata creation in tDAR.
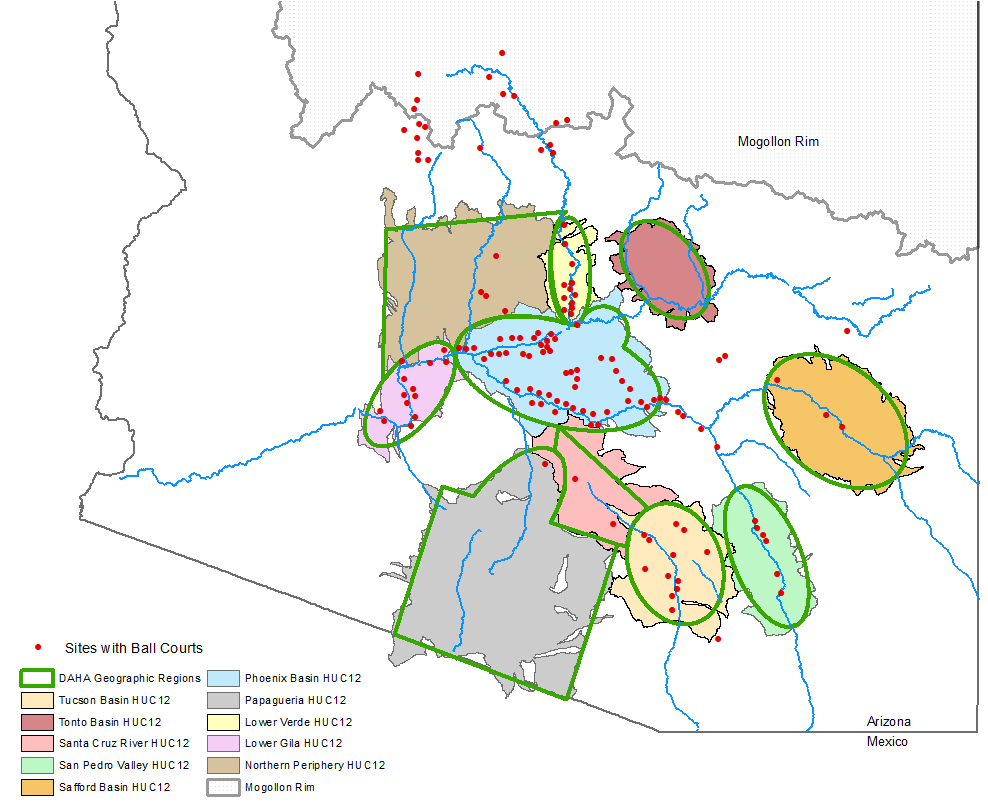
USGS drainage basins (HUC 12) as templates for Huhugam subareas
We are aware that there is no consensus on the exact location of the edges of each subarea, and intend our boundaries to be “fuzzy” – conveying a general sense of place only. To help in delineating the subarea boundaries we looked at the Hydrologic Units mapped at various scales by the USGS (HUC = Hydrologic Unit Code). We merged adjacent HUC 12 drainage basins, smoothed the edges, and used these to outline each of the sub-areas (map above).
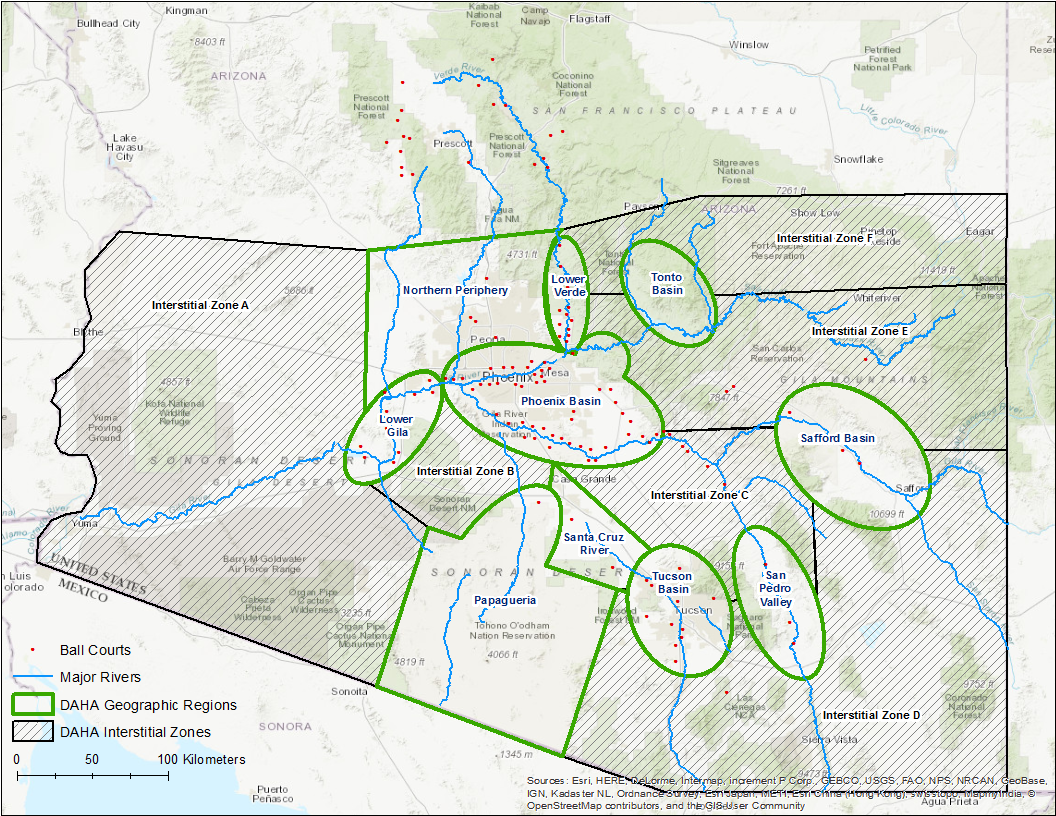
The Huhugam regional system also includes large tracts that are not in a major river basin, and are not part of a named subarea, but are nevertheless important areas that were traversed and utilized in a variety of ways. We’ve designated these as Interstitial Areas and together with the geographic subareas, they provide a geographic framework for the DAHA project (map below).
Map of the Huhugam geographic subareas and Interstitial areas
David R. Abbott, Alexa M. Smith, and Emiliano Gallaga
2007. Ballcourts and Ceramics: The Case for Hohokam Marketplaces in the Arizona Desert. American Antiquity, 72(3), 2007, pp. 461-484.
Craig, Douglas B. (ed.)
2001. The Grewe Archaeological Research Project, vol. 1: Project Background and Feature Descriptions. Anthropological Papers No. 99-1, Northland Research, Inc. Tempe, AZ.
Wilcox, David R. and Charles Sternberg
1983. Hohokam Ballcourts and their Interpretation. Cultural Resource Management Division, Arizona State Museum, University of Arizona. Tucson, AZ.
The project has commitment from the following organizations to supply reports to be entered in DAHA. If your organization would like to join the list of partners, please contact the Center for Digital Antiquity comments@tdar.org.
Amerind Foundation
All published and unpublished reports including seminal publications on sites in Southern Arizona and Chihuahua.
Archaeology Southwest
Huhugam reports produced by Archaeology Southwest (formerly, Center for Desert Archaeology)
Arizona Museum of Natural History
Reports documenting work at Phoenix/Mesa area Huhugam sites such as Mesa Grande, another large Huhugam settlement, over the course of 34 years
ASU Center for Archaeology & Society
Reports that describe the ASU Office of Cultural Management’s seminal archaeological work on Huhugam sites in the Phoenix and Tonto Basins
ASU Libraries, Archives and Special Collections
Reports abd maps, from early 20th century Huhugam research – the Frank Midvale Papers Collection and the Odd S. Halseth Photographic Collection: Pueblo Grande Photographs 1929 – 1960
Desert Archaeology, Inc.
Anthropological Papers and Technical Reports describing projects from Desert Archaeology’s 32 years of research in the Phoenix and Tucson basins
EcoPlan Associates, Inc.
Reports that describe the results of EcoPlan’s archaeological projects in the Phoenix Basin over the course of 16 years
Logan Simpson Design, Inc.
Reports that document Logan Simpson’s excavation and testing projects in the Phoenix Basin, primarily the Phoenix metro area
City of Phoenix, Pueblo Grande Museum
Reports and documents that describe a century of research at Pueblo Grande, a major Huhugam settlement with the largest platform mound in the Phoenix Basin; several series of reports that describe work at other large archaeological sites in the Phoenix metro area
Rio Salado Archaeology
Reports documenting Rio Salado’s 9 years of archaeological research in the Phoenix Basin
Statistical Research, Inc. (SRI)
Reports that describe SRI’s archaeological work in the Phoenix and Tucson basins over the course of 30 years
USDI Bureau of Reclamation (BOR), Phoenix Area Office (PXAO)
Reports documenting decades of archaeological investigations and cultural resource management projects on the lands and waterways that the federal agency manages in central and southern Arizona