By Rachel Fernandez and Mary Whelan

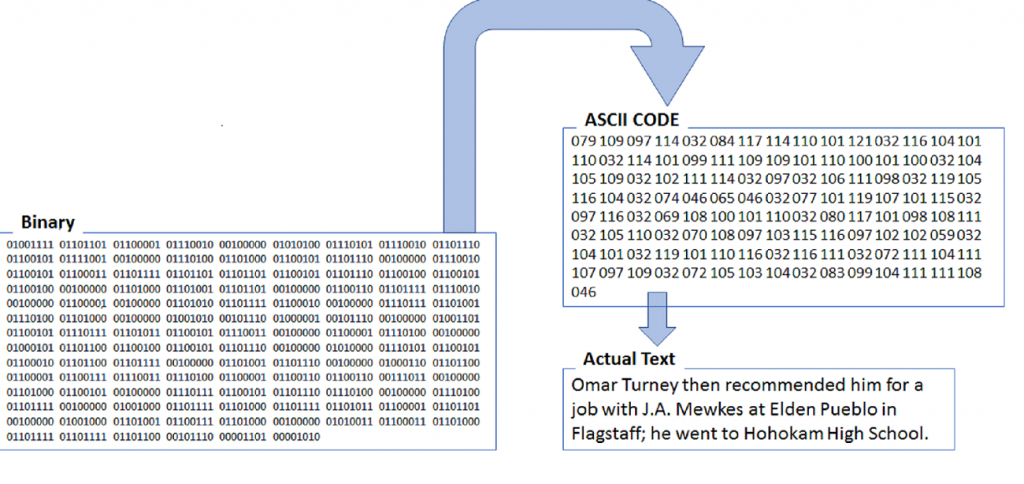
If you Google “archaeology” and “text mining” you get a pretty small number of results. While both the Archaeology Data Service (ADS) in the UK and Open Context, the American open data and publication service, have worked on projects that apply text mining techniques to archaeological reports, it is probably safe to say that most archaeologists are unfamiliar with how text mining or data science can contribute to archaeological research. This isn’t surprising since most of us specialize in the analysis of some material culture product, not the analysis of written reports. But as McManamon et al. (2017) have pointed out, the volume of new archaeological articles, books, compliance reports and other documents is so large, and grows so quickly, that no one person can possibly read it all. Text mining offers automated approaches that help with this “data deluge.”
This past April, the Digital Archive of Huhugam Archaeology (DAHA) team hosted an NEH-funded research workshop focused on Archaeology and Text Mining. Led by DAHA investigators Michael Simeone, Keith Kintigh and Adam Brin, we invited 9 panel experts including archaeologists, Native American scholars, and Digital Humanities researchers, to meet with the DAHA team for a day of discussion. We asked the panelists first to simply talk about how they use digital texts in their work, regardless of their discipline.
Working in small groups, the participants discussed the epistemology of research for their respective fields and quickly turned the conversation to the how text mining digital documents could benefit each field. Ideas such as pulling artifact counts and site descriptions from standardized CRM reports to demographic studies were mentioned. Professor David Abbott, a Huhugam Researcher in ASU’s School of Human Evolution and Social Change, brought up the potential for text mining to advance synthetic research.
Next, we wanted to hear their ideas about how we might make the DAHA digital text corpus more useful to a broad and diverse audience with text mining. Joshua MacFadyen, Assistant Professor of Environmental Humanities in the School of Historical, Philosophical, and Religious Studies, and the School of Sustainability at ASU, brought up this important question on user experience and how we are able to record and trace this impact of these tools on a diverse user group. In addition, David Martinez, member of the Gila River Indian Community and Associate Professor of American Indian Studies at ASU, hopes that this technology can potentially bridge the gap between community users and researchers and allow the users to interpret data in ways that interest these communities. Overall, text processing was thought to be most useful in aiding filtering and analysis of data, rather than providing direct insights.
Finally, we asked all the participants to reflect on what we accomplished and identify useful directions the DAHA team can take in using Text Mining tools and technology. Some of the possible features to come out from DAHA include: automated tools for the extraction of specific text sections, such as tables, references, or headings, use of ontologies to make documents more efficient, topic related searches, and the ability to gather set of reports and have the data linked to its various sources.
The DAHA grant proposal focused specifically on Natural Language Processing applications for text analysis. But during the workshop, a number of more general Text Mining approaches were mentioned, including:
- Corpus Statistics (Word frequencies across corpus)
- Concordance
- N-Grams
- Advanced queries across multiple texts
- Named Entity Recognition
- Topic Modeling
- Sentiment Analysis
- Network Analysis
- Text visualization options
- GeoParsing (geographic information extraction)
If you are interested in applying text mining tools to a document corpus of importance to you, there are several good, open source toolkits that support one or more approaches:
- AntConc (http://www.laurenceanthony.net/software/antconc/ ) is an easy-to-use set of tools for analyzing any type of text corpus. AntConc provides tools to calculate word frequency, concordance, N-Grams, and corpus statistics.
- ConText (http://context.lis.illinois.edu/ ) is a package of tools that allow you to do topic modeling, sentiment analysis, parts-of-speech analysis, and visualization of a text corpus.
- MALLET (http://mallet.cs.umass.edu/index.php ) MAchine Learning for LanguagE Toolkit is a very popular topic modeling tool.
- Ora-Lite (http://www.casos.cs.cmu.edu/projects/ora/software.php ) is a software package that helps you identify and visualize networks (e.g., people who communicated with each other or places that are linked) in text data.
- Voyant (https://voyant-tools.org/docs/#!/guide/start ) is a free online service that supports a number of corpus analysis tools, including visualization.
_______________________
1 McManamon, Francis P., Keith W. Kintigh, Leigh Anne Ellison, and Adam Brin. 2017. “The Digital Archaeological Record (tDAR): An Archive – for 21st Century Digital Archaeology Curation” Advances in Archaeological Practice 5(3), pp. 238–249.
